TrueBlocks: First Quarter 2020 Update
What have we been up to in 2020
This is short update on what we’ve been doing since receiving so many wonderful grants during the GitCoin CLR matching fandango. This money goes a long way. It allows one of us (Rush) to make a trip to EthDenver, where he will be judging some hacks. It has also paid for some much needed help developing the React frontend. If you donated (or even if you didn’t), and you’re in Denver this week, seek me out. I’ll be happy to share our latest work.
We’ve accomplished three primary things so far this year: (1) nearly finished trueblocks-core (our backend), (2) made significant progress on the frontend (trueblocks-docker), and (3) invented the idea of user-centered blockchain exploring.
Progress on the Backend
In the fall of 2018, we received an Ethereum Foundation grant intended to help us complete the TrueBlocks backend, which is not yet done, but it’s pretty close. Our backend is thoroughly covered by about 1,500 test cases, so it’s easy to extend and change at this point.
There are two primary things yet to complete: (a) user onboarding, and (b) documentation. We’ve delayed these two things because we feel that building the frontend will help us understand better how onboarding should work. When one is building local-first, fully-distributed apps, it’s not at all clear how things work until you get them to work…
Progress on the FrontEnd
We’ve made excellent progress on our frontend. We started by building a Javascript / React / Redux application, but we plan to port it to Typescript / Electron soon. (Eventually — when the world catches up — we’ll throw away both versions and the entire web-centric stack and write a truly native distributed app.)
The current version is partially documented (we’re documenting as we go) and has testing built in from the start. Improvements on both fronts.
One thing has become very clear: the more we build, the more excited we get. Local-first, distributed-to-the-edge software is very different than the web-based old-fashioned mess of the current stack.
Here’s a nice picture of our current app, which we’ve taken to calling the TrueBlocks Account Explorer:
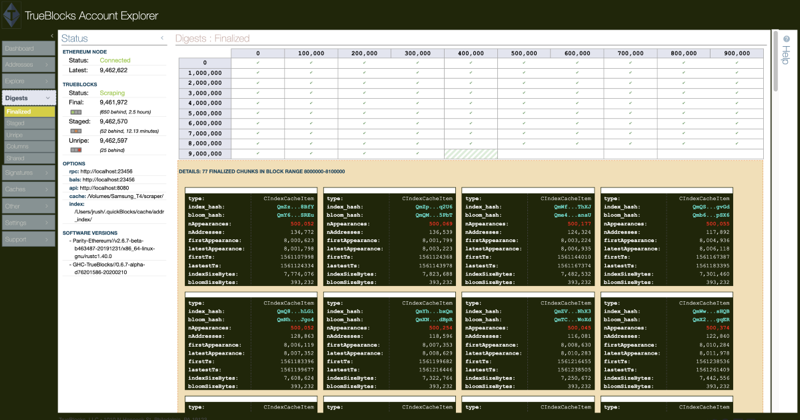
This is a screen shot of the ‘Digests’ page which gives the user insight into the ‘chunks of the index of appearances.’ We’ve written about this elsewhere and thelsewhere (sic).
We’ve learned a lot of unexpected things while building this app out (some of them may seem obvious):
- Local-first software has a single user. Unlike old-fashioned web-based software, local-first software does not need to serve 100,000 of users. This means it doesn’t really have to scale. There’s a single user! The node software will have to scale, but that doesn’t mean the local-first, single-user piece of software has to scale. Your app serves a single user. There are things you can’t give them (historical views into huge smart contracts, for example), but the things they want (insight into their own interaction with the chain) is easily delivered.
- The node can easily deliver data, but it doesn’t have an index. If you know what you’re asking for, the node is a pretty good data delivery system. The trouble with the way the node software currently works is that it doesn’t have an index of address appearances, so it’s impossible (actually, possible but very slow) to get a historical list of transactions. This is what TrueBlocks solves. It allows you app to quickly get access to exactly the transactions your user is interested in.
- Immutable data and indexed databases do not work and play well together. Every time you add a record to a database, it sorts the index (that’s indelibly embedded in what an index is). This means the ‘contents’ of the index file changes. This means the content-addressable hash of the index file changes. This means you can store your index on an immutable data store. Solution: chunk the index. After a certain amount of accumulated data, stop adding to that chunk, write it an immutable store, and move on to the next chunk. This means slower searching, but it means you can share the data, and once you do, you can’t take it back — that is — you can’t capture it. This compromise between immutability and speedy searching promotes decentralization.
- Modern SSD hard drives are tremendously more capable than they need to be for a single user. You can eliminate the database entirely which makes maintaining the immutability of the data and sharing it profoundly easier (with IPFS, for example). Databases, which seem to want to index the shit out of everything, don’t work well with immutable data stores. Luckily, with local-first software, you can eliminate the database (if you choose to). You can write your data and read it directly from disc. Think about — MS Word doesn’t use a database. MS Excel doesn’t use a database. There’s a reason for this — there’s no database because there’s no need for a database.
- The distinction between trusted data and untrusted data becomes very clear. Trusted data is anything from the node (or anything derived deterministically from the node). Untrusted data is everything else.
- Trusted data has three different manifestations— data retrieved directly from the chain (such as block data), data derived deterministically from data retrieved directly from the chain (such as average daily gas usage), and data deterministically derivable from its input (the four-byte function signatures of an ABI definitions, for example). The “True” part of the word TrueBlocks refers to the second and third types of data.
- Untrusted data is any data from the outside world. This type of data includes data produced by the end user (such as names associated with an address — for example your user names address 0x12345 as “Main Wallet” — this type of data should remain private unless the user chooses to share it), and data produced by a third party (price data, insight from blockchain analytics engines, blockchain APIs such as Amber Data or Aleth.io )— this data is very undesirable because of the possibility of manipulation, incorrect calculation, malicious alteration and eventually user capture). We try to do everything we can without this type of third-party data.
- A million other insights. Many of the things we’ve realized are are only obvious once one ventures away from the database-centric, old-fashioned, slow, costly-to-scale web stack shit storm that is the current world of software engineering. For example, why does my front end have 43,102 dependent files? Who wrote them? How safe are they?
User Centered Blockchain Exploring
We claimed above we invented the idea of user-centered blockchain exploring — maybe, maybe not, but I do think we’re the first team to have actually implemented it. Here’s another fine screen shot:
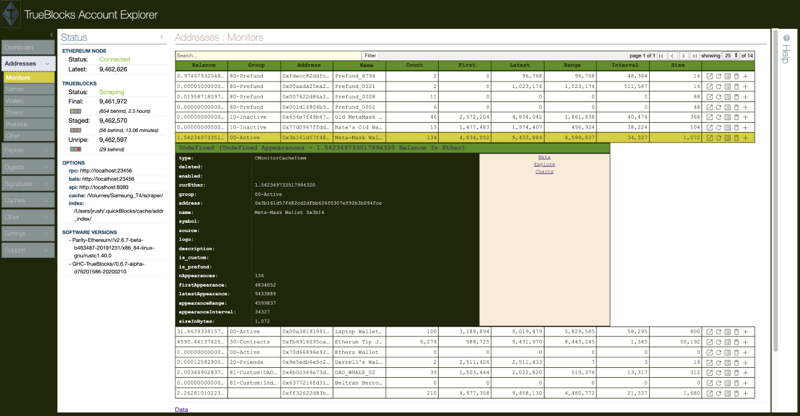
This is the ‘skinned’ Monitors page of the TrueBlocks Accounts Explorer (TrueBlocks frontend allows you to change your skin!) Here, we’re showing a list of addresses that are being actively monitored. From this page, one can access the Explore page which allows you to scroll through the history of the account(s), seeing ‘everything that ever happened to the account.’ (That last sentence is what we’ve been working on for four years.)
Unlike web-based explorers, where the data has been extracted prior to the user interacting with it, out application actively scrapes the data from the chain as being displayed. (The data is subsequently cached to improve performance — caching immutable data is very straight forward).
Because we want to run on small machines (laptops, desktops), we don’t have the luxury of extracting the entire Ethereum data structure into a fast database prior to the user telling us what she’s interested in. Instead, we extract only the index, delaying further extraction until the user tells us what she wants.
When the user asks us to monitor an address, then and only then, do we extract the history of only this single address. This keeps non-database database small (MBs instead of 10s of TBs needed to extract prior to user instruction). This is why our system works on a laptop. The index gives us the ability to extract exactly what the user wants—her transactions and no other.
This is what we mean by User-Centric Blockchain Browsing™. If we didn’t invent the idea, we definitely invented those words.
EthDenver and Beyond
We’re going to be in Denver this week, and we would be very pleased to share more of our work with you. Hit me up at my twitter account (@trueblocks) or by email (see our website http://trueblocks.io). We’ll also be attending EthBerlin and Berlin Blockchain Week this year. Maybe we’ll have a chance to speak there.
Conclusion
When your application has but a single user, everything get simpler. You don’t have to worry about your app staying in memory to stay snappy — spawning processes and reading no-parse binary files every time the user clicks works perfectly. You don’t need a database — you don’t have to protect against concurrent writes, you don’t have to lock files, you don’t have to parse strings, you don’t have to do anything — just load the data directly into memory, cast a data structure on top of it, and you’re off to the races.
Help us with out work. Visit our GitCoin grant page here: https://gitcoin.co/grants/184/trueblocks, and donate today.
If you’d rather not expose yourself to scrutiny, and you’d still like to donate, send ETH to 0xf503017d7baf7fbc0fff7492b751025c6a78179b.
Thanks for reading.