A Long Winded Explanation of TrueBlocks
How TrueBlocks indexes the Ethereum blockchain
Recently, I was engaged in a tweetstorm with Nick Johnson, for whom I have deep, deep respect. The storm was about the topic of indexing the Ethereum blockchain. As is usually the case with my tweetstorms, I don’t think I explained myself well during the thunder and lightning, so I thought I’d take a moment during the lull to better explain myself. So this is an explanation for Nick (and anyone else who’s listening) about how TrueBlocks indexes the Ethereum blockchain.
Chifra
The first thing I want to discuss is a command line program we’ve written called chifra. Like git, chifra is an overarching tool that gives access to many other tools. Here’s the help screen:
Accounts:
list list every appearance of an address anywhere on the chain
export export full detail of transactions for one or more addresses
monitors add, remove, clean, and list address monitors
names query addresses or names of well known accounts
abis fetches the ABI for a smart contract
Chain Data:
blocks retrieve one or more blocks from the chain or local cache
transactions retrieve one or more transactions from the chain or local cache
receipts retrieve receipts for the given transaction(s)
logs retrieve logs for the given transaction(s)
traces retrieve traces for the given transaction(s)
when find block(s) based on date, blockNum, timestamp, or 'special'
Chain State:
state retrieve account balance(s) for one or more addresses at given block(s)
tokens retrieve token balance(s) for one or more addresses at given block(s)
Admin:
config report on and edit the configuration of the TrueBlocks system
daemon initalize and control long-running processes such as the API and the scrapers
scrape scan the chain and update the TrueBlocks index of appearances
chunks manage, investigate, and display the Unchained Index
init initialize the TrueBlocks system by downloading from IPFS
Other:
explore open a local or remote explorer for one or more addresses, blocks, or transactions
slurp fetch data from EtherScan for any address
You can see a bunch of interesting tools. We’ll start with one called chifra blocks.
A Simple Tool: chifra blocks
Just to get us started I’m going to discuss a very simple tool called chifra blocks. Like many of the TrueBlocks tools, chifra blocks is in some ways a front-end for the eth_getBlock* RPC calls. For example, one may run:
chifra blocks 1000
and the tool will return the JSON data for block 1000. But as is also true of all TrueBlocks tools, chifra blocks extends the RPC to make it more useful. One simple way it does this is by allowing you to specify block ranges and block steps. So,
chifra blocks 1000-2000:10
exports the JSON data for every 10th block between block 1000 and 2000. There are a number of other options (including exporting to csv and tab delimited data), but I will focus on just one that directly affects the issue of indexing the chain:
chifra blocks --uniq_tx 12000000
exports what we call ’every appearance of every address in the block’. ‘Appearance’ here is an important concept. An ‘appearance’ includes obvious things, such as when an address appears as the from or to address in a transaction, but there are many other ways an address may be an appearance.
An address is an appearance if it is the source of events in the event logs. It can be an appearance as any of the topics of an event. It can be a newly created smart contract, the winning miner for the block, one of the uncles in the block, etc. There are about 20 different places where an address may appear.
TrueBlocks finds them all. In fact, for every 100 ‘appearances’ that EtherScan returns using all four of it’s available APIs for an address, TrueBlocks finds 180 appearances.
The above command returns something like this:
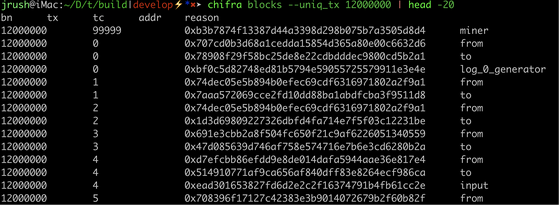
Perhaps you can see the start of an index of appearances in the above output.
Scraping
Ethereum is continually producing data. Every 14 seconds a new block appears.
The next tool I’d like to discuss is called chifra scrape, which, like the chain, runs continually. Each time chifra scrape runs, it looks for new blocks and with each new block, it does a very simple thing: it runs the above --uniq_tx command against the block to extract the list of address appearances in that block. Unlike chifra blocks which simply outputs the list of appearances to the screen, chifra scrape stores the addresses in a file on the end user’s machine.
An important note: the TrueBlocks index is built on the end user’s machine. Getting the data to the end user’s machine is the whole point of decentralization. This ensures both autonomy and--really importantly--speed. Local data is orders of magnitude faster than remote data. This is one of the most important aspects of what TrueBlocks has done.
So, chifra scrape watches every block, extracts every Ethereum address that appears anywhere in that block, and stores those addresses for later lightning-fast querying. Pretty standard stuff, but there’s a serious twist.
A Sort-Of Index
chifra scrape builds an index─sort of. I say “sort of” because the index isn’t the traditional Web 2.0 database index with which you are probably familiar. That is because the data is immutable and we want to keep it that way. We want to make sure we preserve the Ethereum data’s immutability if possible.
A blockchain is a time ordered log of transactions. (We’ve written about this here). The addresses that appear in each transaction are, as a result, interspersed. This is a good thing. Because the data is time ordered, it can be made immutable. As each crumb in the trail of crumbs is laid down, if one ties the crumb to the previous crumbs (with a cryptographic hash), the data cannot be altered. In other words, the time-ordered blockchain data is immutable.

This is what we all love about blockchain data.
An Index is not a Time-Ordered Log
An index contains the same data as the time ordered log, but the data is no longer sorted by time. The data is sorted by whatever is being indexed. In our case, this means the index is sorted by address (below, color represents addresses):

If one is building a time-ordered log, one may simply append new records to the end of the list, leaving the previous data untouched. If, on the other hand, one is building an index, one must sort periodically so that future queries are efficient.
This need for sorting destroys the time-ordered nature of the data -- and therefore it destroys the ability to keep the data immutabile. Worse than that, every time a new address is added to the index, one must re-sort, thereby breaking the immutability of the data over and over again.
We’re stuck in a conundrum. We don’t want to forgo the immutability of the data, but we need to sort the data after every block in order to efficiently query it. (Our goal, eventually, is to make this index available to ourselves and all of our users over IPFS -- and immutable--and super cheap--data store.)
So what to do?
We cannot add new records to the index because it will continually change the IPFS location of the index file. However, we must continually add new records to the index in order to be able to query right up to the head of the chain.
Here’s the solution: after a certain amount of data has accumulated in the index we stop adding new records and create what we call an index chunk. We can then add that chunk to IPFS, and begin a new chunk.
A weird way to say the same thing is to say that we are creating a time-ordered log of indexes of a time-ordered log.
Bloom Filters
Before I move on, a quick note about Bloom filters. Bloom filters are an amazing data structure that do an amazing thing. They represent, in a very compact form, set membership in a data set such as an index.
After creating each index chunk, we also create a Bloom filter in front of that chunk that represents the set membership. In addition to publishing the index chunk itself to IPFS, we publish the chunk’s Bloom filter. The Bloom filter will be seen to be super useful in creating the system that we want to create -- a system that allows us to distribute the index to our end users very efficiently.
Back to the Scraper
The scraper, in addition to querying each block and extracting appearances of addresses continually inserts them into the currently active chunk. Each time it inserts new records, it decides if the index has grown “large enough”. If the index is large enough, the scraper creates a new chunk, creates the corresponding Bloom filter, and publishes both of these files to IPFS, storing away the hash and then it begins accumulating the next chunk.
I won't go into a very interesting discussion of how we decide 'when a chunk is full enough', but let me hint that the decision is easy to do but hard to explain. We do not, as did in the original versions, break the chunks every N blocks. It turns out that is a bad design choice because different blocks contain significantly different numbers of appearances. A much better way to decide when the chunk is full enough is to break the chunks when it contains a particular number of appearances (in our case 2,000,000 records). In this way, each chunk is roughly the same size. We believe this best builds the chunks so that any particular query for an address has a roughly an equal chance of appearing in any given chunk. We will write about this fascinating issue later.
Given a series of chunked indexes, each chunk of which has an associated Bloom filter, we are now ready to get what we want--a list of every appearance for an address.
Querying the Index
Given any address, our applications query the index chunks by scanning through the Bloom filters looking for hits. A Bloom filter is a small and super fast method of determining set membership. If, upon query, the Bloom filter returns ‘yes’ (it actually returns ‘maybe’), then, and only then, do we search the much larger chunk.
If the Bloom filter hits (that is, it indicates that the address may be present in the chunk), we need to open and search the associated chunk.
If the Bloom filter misses, we may skip the index chunk. (A Bloom filter is never wrong when it says a data item does not belong to the set.) We estimate, for any given address for a ’typical’ user, nearly 90% of the Bloom filters miss. This means that the query skips nearly 90% of the index chunks. This speeds up the search significantly.
Note that the Bloom filters are small enough, in total, to store in memory. Additionally, because the index chunks are sorted by address, when we are forced to query the chunk, we can complete a very fast binary search looking for appearances.
The entire process is not as fast as a straight database query because we have to scan the list of blooms, but remember we’re doing this because we want to preserve the immutability (i.e. time-ordered nature) of the data. On a web server, this scanning would be a very bad idea, but our application is not a web server. Our application is local-first software. There is but a single user! In an environment with but a single user, one may do things that do not work on web servers.
Ah, the beauty of local-first software.
Fixed-Width Binary Data is Fast
There’s another thing that makes the index search lightning fast, That is that we store the index chunks directly as bytes of fixed-width records. This means we do not have to parse the data as it’s read from the disc. I cannot stress enough how much faster this is than parsing the file while reading it. We don’t serialize. We don’t parse. The data is read directly from disc into memory as an array of fixed-width records. Computers are really good at this.
When we’re forced to load a full index from disc, we simply blast the bytes into memory. The index chunk is already sorted, so we can immediately do a fast binary search for the address. Each record in the array is 20 bytes wide for the address and four bytes each of the blockNumber and transactionIndex. In C++:
struct CAddressRecord_base {
uint8_t bytes[20];
uint32_t offset;
uint32_t cnt;
};
A bit old-fashioned, but extremely fast and portable.
Using the Index
Once in possession of the chunked index we can finally use TrueBlocks to do what we want to do: query for a list of every appearance of an address anywhere on the chain.
We’ll use the TrueBlocks public wallet in the following examples. First, we’ll remove the address from any caches just to make sure we’re not? starting from a known place:
chifra monitors --delete 0xf503017d7baf7fbc0fff7492b751025c6a78179b
Next, we list the appearances for this address:
chifra list 0xf503017d7baf7fbc0fff7492b751025c6a78179b
If you run this command (and your scraper is caught up to the front of the chain), you will see that chifra scans the Bloom filters, opening the index chunks only if the Bloom filter hits.
If the address appears in the chunk, chifra caches that appearance (again in a fixed-width binary file). The next time we list the transaction appearances, chifra first updates to the front of the chain and then responds very quickly because the history has been cached.
This points to a very important aspect of TrueBlocks.
TrueBlocks never extracts a piece of data from the chain until that data is needed. Nor does TrueBlocks cache any data until the user instructs us to by querying for that data.
Notwithstanding this, once the user tells us to extract a piece of data, we cache it very aggressively. This is why TrueBlocks works on desktop machines. We write a minimal amount of data at any given time. Unlike regular ETL processes from Web 2.0, where all the data is fully extracted at the beginning, then all the data is fully transformed at the beginning, none of the data in TrueBlocks is extracted until it’s requested by the user.
This is very different to Web 2.0 (and every other Web 3.0 data pipeline that we’re familiar with). This is why TrueBlocks is alone in the Ethereum space in being able to run on the end-user’s local machine.
I think a very good definition of decentralization is that the system allows individuals to access a system’s data locally without asking a ‘service provider’ for access to that data. As long as the user has access to a node (see TurboGeth) and the TrueBlocks’ index, that user has access to any piece of data they want about their own (or anyone else’s) addresses. (As long as they have enough room on their computer’s hard drive -- the point being that the size of the hard drive should be the decision of the end user, not the system designer.)
What to do with a List of Appearances?
Now that we have a list of appearances, what can we do with it?
The list of appearances is very small. It’s stored in a small binary file with the same name as the address. For any given address, this file (which we call a monitor) contains an array of two integers: blockNumber and transactionIndex.
The files are very, very small. Even the most heavily-used smart contracts such as UniSwap, which appears multiple times in almost every block, takes up only a few 100 MBs. The addresses of most of our expected users will take up on 10s of kilobytes.
Note that we have not yet extracted the transactional details of the transactions. We’ve only extracted the locations of the transactions. Remember, we never extract anything until we’re told to.
In order to extract the transactional details for the address, we use another chifra command:
chifra export 0xf503017d7baf7fbc0fff7492b751025c6a78179b
Finally, we’re extracting transactional details from the chain (and we’re caching that data, as you might expect). Notice that we are not caching entire blocks of data -- only the individual transactional details for only the addresses we’re interested in.
We store transactions in our cache by blockNumber and transactionIndex. In this way, if another address happens to be involved in the same transaction, the transaction is cached only once. We're very careful about how much data we write to disc.
Notwithstanding our desire to store minimal data, during a transaction’s extraction, we also extract the transaction's receipts and all of its logs. We find that it is almost always the case that this data is needed to fully understand any given transaction. If we're doing accounting (Ether or token accounting), we also extract the transaction's traces, but only if they are needed to make the accounting reconcile.
There are a number of very useful options to the chifra export command:
-
--appearances list only the appearances for the address
(identical to the list option)
-
--accounting causes accounting statements to be exported for
each transaction
-
--tokens extends the --accounting option to include token
as well as ether accounting
-
--receipts exports only the transaction’s receipt
-
--logs exports only the transaction’s event logs
-
--traces exports all traces for the transactions
And, a very important option, --articulate which reads any smart contract’s ABI and presents the ugly Ethereum byte data as English language text. (This last is super helpful in aiding the understanding of the data, but unfortunately is centralized by querying EtherScan.)
Note that all the chifra tools provide a few very helpful options
such as exporting its data as either json (the default), csv, or
txt. The flexibility of the output allows us to support many uses
such as our GitCoin data dump site
(https://tokenomics.io/gitcoin/),
or send it over an API to a front end application as we do for our
TrueBlocks Explorer application (using the chifra serve option).
This is what we mean by decentralization.
Upshot
I respect Nick Johnson immensely, but he's incorrect. It is possible to index the Ethereum blockchain effectively on a small machine.
Extending the Ethereum Node using Turbo Geth
Last summer, we spent time looking closely at the TurboGeth codebase. As a result, we got super excited about the possibility of our work being incorporated in the node (as an extension, not a core component). Turbo Geth has shown that it’s possible to lessen the size of the Ethereum data from 7TB for OpenEthereum to only 1TB for TurboGeth. This means the dream of running on smaller hardware remains alive. More nodes. More locally.
TurboGeth adds something else to the equation. TurboGeth allows individual developers or groups of developers to build their own custom synchronization stages. Effectively, this is what the TrueBlocks chifra scrape is. We’ve convinced ourselves that the TrueBlocks scraper (which is written in Go) can be implemented as a custom TurboGeth stage and we intend to do that as soon as we have the opportunity.
Summary
We’ve shown that:
-
The Ethereum node is broken,
-
The thing that is broken is that the node does not have an index,
-
It is impossible to simultaneously build an continually-growing
index and deliver that index over a content-addressable immutable store such as IPFS,
-
In response to this impossibility, one must chunk the index (that
is, create a time-ordered log of indexes of a time-ordered log),
-
Placing a Bloom filter in front of a chunked index wildly speeds up
the search of the index,
-
In order to properly work on an end user’s machine, the system must
write things to the hard drive only when the user instructs the system to do so,
-
It’s possible to index the Ethereum blockchain
-
Indexing the Ethereum blockchain is a small data problem, not a big
data problem
Closing Remarks
Following is a list of ideas and concepts that did not fit well in the above discussion. They are included here as a placeholder and a promise for future articles.
[TrueBlocks gets better with more users - a natural network effect]
TrueBlocks is able to share the index it builds at near-zero cost, as explained on this website: https://unchainedindex.io. Additionally, the way we store the index on IPFS means the system gets better and cheaper as more and more users use the system. This is opposite to the way current web economics work. Currently, with a website, the more users the website gets, the more expenses are incurred in order to provide the same level of service. This is because the entire burden of running the infrastructure is on the people who run the server. In Web 3.0 / content-addressable data environment, the more users the system gets, the more those users themselves help build and manage the infrastructure.
If two people download and pin the TrueBlocks Bloom filters on IPFS, they are twice as likely to be found. This aspect of the system grows exponentially. The more users the system acquires, the more likely each new user is to find the data she’s looking for (assuming all users are pinning the data they use), and users will pin the data because they want to have it FOR THEMSELVES.
[Heavy Users Carry a Heavier Burden. Light Users a Lighter One.]
One of the natural outcomes of the way our system works is that heavy users--those that appear in almost every block--will naturally download, pin, and carry a larger portion of the index. If an address is super-active, it will be in every chunk. For most users, however, they only interact once in a while. For example, our address only appears in around 40 chunks. This seems naturally fair to us. Small users carry a small burden. Larger users carry a larger burden.
[Tiny Footprint]
The footprint of the initial installation of the TrueBlocks system is small. Only the Bloom filters need to be installed at first. As the user scans the Bloom filters looking for address appearances, interesting chunks need to be downloaded from IPFS. Once downloaded, the chunk can then be searched and pinned on IPFS if the address is found thereby making that chunk more likely to be found in the future by other users. Furthermore, the end user will have the file locally, making it significantly faster.
[Users Store More than Just Their Own Data]
Another aspect of the system is that each user stores a little bit more data than he/she needs for his/her direct needs. Some systems that we know of store each transaction or each block separately on IPFS. We don’t think this works. One does not get the benefit of one person storing another person’s data. We purposefully require users to store a tiny bit more data than they actually need. In this way redundancy is increased and the whole system improves as each new user joins the system.
[TrueBlocks Data is Provably True]
In addition to all of the above, the TrueBlocks data is also provably true. We prove our data by inserting into the data itself the git commit hash of the software instructions (i.e. the code) that builds the index chunks and Bloom filters. This hash is inserted into the manifest file that we use to report the location of the data to our software.
The manifest is updated during the creation of each chunk by storing the IPFS hashes of the chunk and the associated Bloom filter, adding the IPFS hash of the file format for both the chunk and the Bloom filter and the above mentioned git commit hash into the manifest. Each manifest includes a hash to the previous manifest, so the user may walk his/her way backwards through the data. We then store the manifest on IPFS as well. Finally, we publish the IPFS hash of the manifest to an Ethereum smart contract. See the above mentioned UnchainedIndex website for more information.
In this way, our end-user applications always know where to go on IPFS to get the Bloom filters. The app simply queries the Unchained Index smart contract to find the latest hash of the manifest. Upshot - zero cost to publish the data. Everyone has access to the data at all times if they have access to the Ethereum chain.